Le crawling est un processus central de Google. Ses robots analysent les sites pour déterminer leur positionnement sur le moteur de recherche. Être premier sur Google n’est possible que si ses robots ont jugé le site pertinent, plus que les autres. Pour cela, il faut connaître et respecter les algorithmes de Google. En répondant à leurs différents critères, le site sera bien référencé.
Comment fonctionne le crawling ? Quelle différence avec l’indexation ? Comment faire pour que le site soit crawlé, et puisse être bien placé sur Google ?
Petit point vocabulaire
Avant tout, faisons un point de vocabulaire afin de ne pas confondre un terme avec un autre.
- Crawler : scanner, analyser une page web pour comprendre sa structure et son contenu.
- Indexer : permettre à Google de connaître la page et de l’afficher dans les résultats de recherches.
- Référencer : faire en sorte qu’une page web soit la mieux positionnée sur Google.
En SEO, on parle de crawling lorsque Google envoie un robot analyser une page pour faire sa connaissance et savoir de quoi elle traite. Suite à cela, Google pourra l’indexer et la présenter aux internautes, sauf si on lui donne l’ordre contraire. Si la page respecte les critères des algorithmes de Google, celui-ci l’affichera au-dessus des pages déjà existantes : on dit alors qu’elle est bien référencée.

Le déroulement du crawling de Google
Que regardent les robots de Google lorsqu’ils crawlent un site ?
Mais justement, quels sont les critères des algorithmes de Google ? Quels sont les éléments qu’analysent ses robots lorsqu’ils crawlent un site ?
Ils analysent 3 types d’éléments :
- la technique : le site est-il correctement construit ? Les robots peuvent-ils le trouver et venir dessus facilement ?
- le contenu : quel est le sujet de la page ? Le texte est-il pertinent pour les internautes ? Répond-il précisément à leurs questions ?
- la popularité : le site est-il vu comme étant une référence dans son domaine de la part des autres sites de la même thématique ?
Si un site web répond à ces critères, il a de bonnes chances d’être bien vu par Google et d’être bien référencé.
Comment Google crawle nos sites ?
Le robot de Google a un parcours assez aléatoire dans lequel il se déplace de lien en lien. Dès qu’il croise un lien, il va voir ce qui se cache derrière et donc découvrir une nouvelle page pour l’analyser.
D’où l’importance des liens sur internet, qu’ils soient internes ou externes. Les liens internes permettent aux robots de Google de connaître un maximum de pages de votre site, et de rester longtemps sur celui-ci sans aller visiter d’autres sites. Plus le robot reste longtemps, plus il analyse en profondeur le site, et meilleur peut-être son référencement.
Il est également important de placer le lien de votre site chez les autres sites : ce sont les backlinks. Lorsqu’il sera chez un concurrent, le robot croisera votre lien et vous rendra visite. Plus vous avez de backlinks, plus souvent le robot trouvera votre site.
Pourquoi Google crawl-t-il nos sites ?
Google crawle nos sites pour évaluer leur pertinence et leur autorité. Si l’évaluation est concluante, le site sera bien positionné sur le moteur de recherche.
Mais Google a énormément de travail à faire. Il est 11h02 quand je rédige cet article, et d’après Worldometer, déjà plus de 4 millions d’articles de blog ont été publiés aujourd’hui dans le monde. Des articles que Google doit donc prendre le temps de crawler pour ensuite les classer et les proposer aux internautes.
Comment faciliter le crawling de Google ?
Il convient alors de lui faciliter le travail en créant un site de qualité et en structurant correctement ses pages. Chacun de vos articles doit-être en mesure d’accueillir chaleureusement Google. Voici quelques astuces pour y parvenir :
- optimiser l’URL pour faciliter la lecture des robots ;
- alléger le temps de chargement, notamment en compressant les images que l’on publie ;
- rédiger une introduction riche sémantiquement pour que Google puisse comprendre, dès les premières lignes, de quoi traite le texte.
Le crawling et l’internaute
Google analyse également l’internaute afin de lui proposer le contenu dont il a besoin.
En effet, il connaît vos informations personnelles et notamment :
- le lieu géographique où vous êtes connecté ;
- votre âge ;
- votre sexe ;
- vos recherches antérieures…
C’est pour cette raison qu’en recherchant par exemple “pizzeria”, les restaurants proposés seront ceux qui sont dans votre ville. Google n’a aucune raison de vous proposer des établissements situés à l’autre bout du pays.
En connaissant votre profil, Google peut vous proposer des résultats pertinents, mais également cibler les publicités en fonction de vos centres d’intérêt.
Indexer une page pour permettre le crawling
L’index de Google est une bibliothèque dans laquelle il range les documents qu’il a examiné et trouvé intéressants.
Si une page n’est pas indexée, cela signifie que Google ne la connaît pas encore. Comment vérifier cela et comment y remédier si ce n’est pas le cas ?
Savoir si une page est indexée
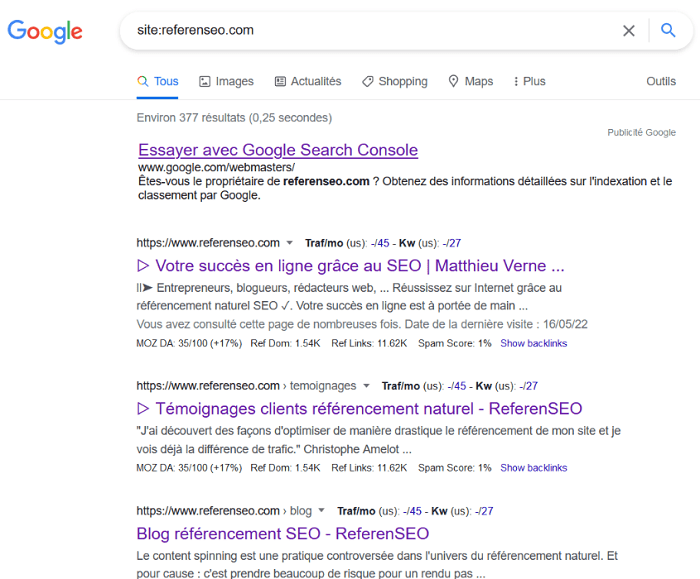
Pour savoir si un site est connu par Google, il suffit de connaître une simple formule :
➡ site:nom du site
Toutes les pages du site qui sont indexées seront alors affichées. Si vous souhaitez vérifier l’indexation d’une page précise, il suffit de faire la même manipulation en renseignant le lien de la page. S’il n’y a aucun résultat, la page n’est pas indexée.
Connaître les pages indexées d’un site
Indexer une page
Il est possible d’indexer simplement une page en utilisant le logiciel Google Search Console. Entrez l’URL de la page en question dans la barre de recherche qui se situe en haut, puis appuyez sur la touche Entrée de votre clavier. Une recherche prenant quelques secondes sera effectuée. Par la suite, il sera indiqué si l’URL est sur Google ou non. Si ce n’est pas le cas, vous pourrez cliquer sur le bouton “demander une indexation”. L’opération sera effectuée dans les prochains jours.
Il est aussi possible d’indexer ou non une page directement sur WordPress avec Yoast SEO, en cliquant sur Avancé.
Indexer une page avec WordPress
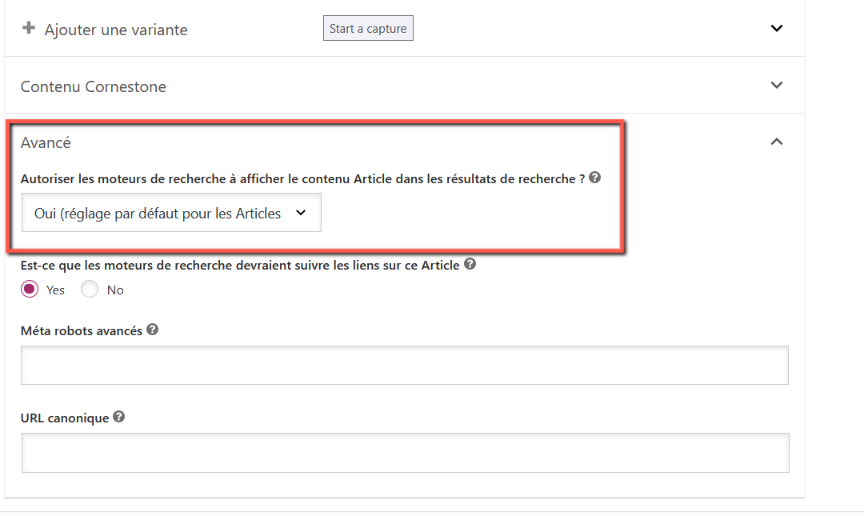
Il est parfois préférable de ne pas indexer une page. C’est le cas des mentions légales, qui n’apportent rien à votre business. Il est inutile de les trouver sur Google, donc inutile de faire perdre du temps à son robot en lui demandant de les analyser.
Savoir quand est venu le robot de Google pour la dernière fois
Il peut être utile de savoir quand est venu le robot de Google pour la dernière fois.
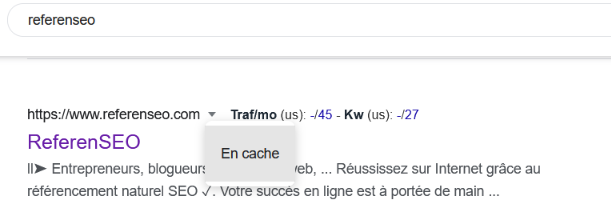
- Commencez par taper le nom de votre site sur Google
- Cliquez sur la petite flèche qui se trouve à droite de l’URL, puis sur En cache.
- La date et l’heure du dernier passage du robot sera indiqué.
Dernière visite d’un robot de Google sur un site
Date et heure du dernier passage du robot de Google

Si vous avez effectué des modifications, par exemple changé le Title, après la date et l’heure indiquée, Google n’est pas encore au courant de ce changement. Il affichera l’ancienne version, jusqu’au prochain passage du robot.
Plus votre site a de backlinks, plus il viendra régulièrement. Par exemple, il peut ne pas visiter un nouveau site pendant plusieurs semaines.
Pour inciter le robot à venir, vous pouvez publier un nouvel article de blog. Il sera alerté et fera de vous l’une de ses priorités. Il pourra tout de même mettre quelques jours à venir. Si votre nouvel article n’est pas indexé naturellement une semaine après sa publication, vous pouvez demander son indexation sur Google Search Console.
Le crawling, la mission complexe du robot de Google
Ce robot a une mission complexe car il doit analyser chacune des pages récemment publiées : c’est le crawling. Cela lui permet d’en juger la pertinence et de la classer dans les résultats de recherche. L’objectif est de fournir des informations de qualité aux internautes. C’est comme ça que Google a su s’imposer comme un géant du web, et il compte bien le rester. Du coup, son robot est de plus en plus exigeant avec le temps.
C’est pour cela qu’il est important d’avoir une bonne stratégie SEO et de réussir son référencement naturel. Que ce soit dans la construction du site, la rédaction du contenu ou l’acquisition de backlinks, rien ne doit être laissé au hasard.
Le SEO regroupe de multiples actions à faire et à réussir. N’hésitez pas à confier le référencement de votre site à un professionnel, qui vous guidera vers le sommet de Google.
J’ai d’ailleurs tout un réseau de rédacteurs web SEO que je peux vous recommander si jamais vous en avez besoin, alors n’hésitez pas à me contacter !